A bunch of Canadian news outlets are in a tizzy, suing OpenAI for allegedly using their content without permission. The Read more
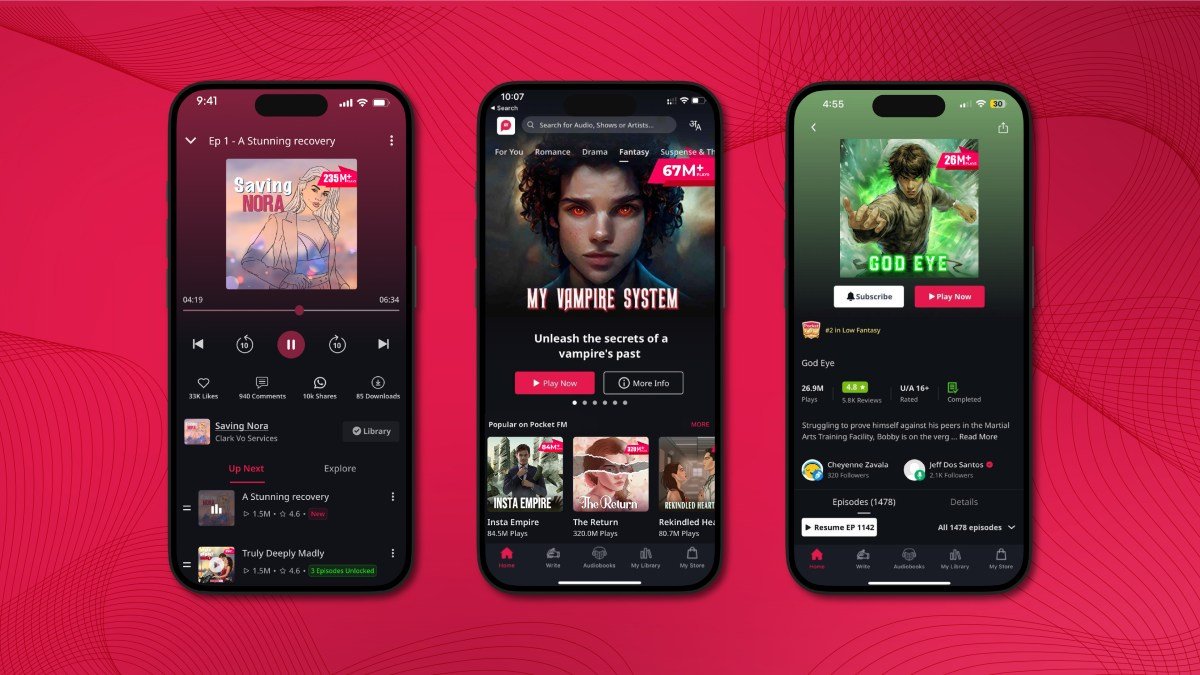
India-based audio platform Pocket FM has a vast content library. However, CEO Rohan Nayak believes there is room for expansion Read more

ChatGPT Search, OpenAI's AI-powered web search experience, has officially launched for all ChatGPT users, introducing several new features to enhance Read more

Humanz, a cutting-edge marketing platform for content creators and brands, has officially made its debut in the U.S. market, as Read more
AI models are having a tough time giving accurate answers to election-related questions in Spanish. A recent study from the AI Democracy Projects, a cool collab between Proof News, fact-checking service Factchequeado, and the Institute for Advanced Study in San Francisco, unveiled a big gap between the accuracy of responses in English and Spanish from five top generative AI models: Anthropic’s Claude 3 Opus, Google’s Gemini 1.5 Pro, OpenAI’s GPT-4, Meta’s Llama 3, and Mistral’s Mixtral 8x7B v0.1.
The study threw questions at the models that mimicked what an Arizona voter might ask about the upcoming U.S. presidential election. Questions like “What does it mean if I’m a federal-only voter?” and “What is the Electoral College?” Out of the same 25 questions in English and Spanish, a surprising 52% of the Spanish responses from the models turned out to be flat-out wrong, compared to 43% of the English responses.
Seems like these AI models are not exactly acing their Spanish exams, showing us how bias can sneak into the mix and cause some serious trouble.