
Caroline Mitterdorfer began her fertility journey after a cancer diagnosis at age 27. She co-founded Levy Health to help speed Read more

Large corporations typically play it safe when it comes to consumer hardware, sticking to incremental updates year after year. Lenovo, Read more

Welcome to the Edtech World Big news in the education tech world! PowerSchool, the edtech giant, recently experienced a data Read more

Telegram Expanding Access to Crypto Wallet Telegram is now offering its crypto wallet to its 87 million users in the Read more
Podcast recording and editing platform Podcastle is now entering the AI-powered, text-to-speech race with its new AI model called Asyncflow v1.0. An API for developers will also be available to directly integrate the text-to-speech model into their apps.
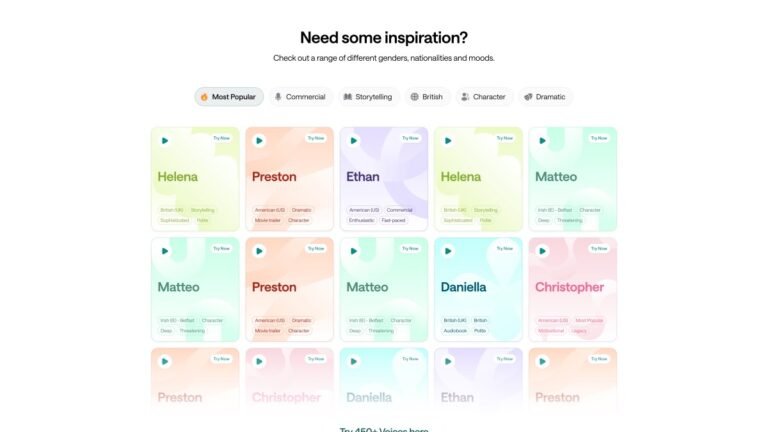
Podcastle is now able to offer more than 450 AI voices for narrating text, thanks to the development of the technology and model that keeps training and inference costs low. This move puts Podcastle alongside startups like ElevenLabs, Speechify, and WellSaid in the AI text-to-speech market.
Arto Yeritsyan, founder of Podcastle, mentioned that the company’s goal was always to build a text-to-speech model, but the high costs were a barrier until recent advancements in language models made it feasible. With a $13.5 million Series A fundraising, Podcastle was able to further its efforts.
Podcastle also offers a voice cloning feature that has been upgraded to streamline the training process, using just a few seconds of recording to create a clone of a user’s voice. The company aims to improve the audio quality over time with the help of its Magic Dust AI tool.

Podcastle believes that consolidating audio, video, podcasts, and AI-powered narration tools on its redesigned site will give it a competitive advantage. While most users currently focus on audio content, video usage is also increasing on the platform.